

Aprendizaje por refuerzo del mundo real completamente autónomo con aplicaciones para la manipulación móvil
El aprendizaje por refuerzo proporciona un marco conceptual para que los agentes autónomos aprendan de la experiencia, de manera análoga a cómo se podría entrenar a una mascota con golosinas. Pero las aplicaciones prácticas del aprendizaje por refuerzo a menudo están lejos de ser naturales: en lugar de usar RL para aprender a través de prueba y error al intentar realmente la tarea deseada, las aplicaciones típicas de RL usan una fase de entrenamiento separada (generalmente simulada). Por ejemplo, AlphaGo no aprendió a jugar Go compitiendo contra miles de humanos, sino jugando contra sí mismo en una simulación. Si bien este tipo de entrenamiento simulado es atractivo para los juegos en los que se conocen perfectamente las reglas, su aplicación en dominios del mundo real, como la robótica, puede requerir una variedad de enfoques complejos, como el uso de datos simulados o la instrumentación de entornos del mundo real en varios entornos. formas de hacer viable la formación en condiciones de laboratorio. ¿Podemos, en cambio, diseñar sistemas de aprendizaje por refuerzo para robots que les permitan aprender directamente «en el trabajo», mientras realizan la tarea que deben realizar? En esta publicación de blog, hablaremos sobre ReLMM, un sistema que desarrollamos que aprende a limpiar una habitación directamente con un robot real a través del aprendizaje continuo.
Para permitir la capacitación “en el trabajo” en el mundo real, la dificultad de acumular más experiencia es prohibitiva. Si podemos facilitar la capacitación en el mundo real, al hacer que el proceso de recopilación de datos sea más autónomo sin requerir supervisión o intervención humana, podemos beneficiarnos aún más de la simplicidad de los agentes que aprenden de la experiencia. En este trabajo, diseñamos un sistema de entrenamiento de robot móvil «en el trabajo» para limpiar aprendiendo a agarrar objetos en diferentes habitaciones.




Para permitir la capacitación “en el trabajo” en el mundo real, la dificultad de acumular más experiencia es prohibitiva. Si podemos facilitar la capacitación en el mundo real, al hacer que el proceso de recopilación de datos sea más autónomo sin requerir supervisión o intervención humana, podemos beneficiarnos aún más de la simplicidad de los agentes que aprenden de la experiencia. En este trabajo, diseñamos un sistema de entrenamiento de robot móvil «en el trabajo» para limpiar aprendiendo a agarrar objetos en diferentes habitaciones.
Lección 1: Los Beneficios de las Políticas Modulares para Robots.
Las personas no nacen un día y realizan entrevistas de trabajo al día siguiente. Hay muchos niveles de tareas que las personas aprenden antes de solicitar un trabajo, ya que comenzamos con las más fáciles y nos basamos en ellas. En ReLMM, hacemos uso de este concepto al permitir que los robots entrenen habilidades reutilizables comunes, como agarrar, al animar primero al robot a priorizar el entrenamiento de estas habilidades antes de aprender habilidades posteriores, como la navegación. Aprender de esta manera tiene dos ventajas para la robótica. La primera ventaja es que cuando un agente se enfoca en aprender una habilidad, es más eficiente en la recopilación de datos sobre la distribución del estado local para esa habilidad.
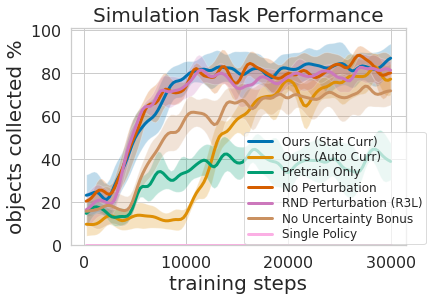
Eso se muestra en la figura anterior, donde evaluamos la cantidad de experiencia de agarre priorizada necesaria para dar como resultado un entrenamiento de manipulación móvil eficiente. La segunda ventaja de un enfoque de aprendizaje multinivel es que podemos inspeccionar los modelos entrenados para diferentes tareas y hacerles preguntas, como «¿puedes captar algo ahora mismo?», lo cual es útil para el entrenamiento de navegación que describimos a continuación.
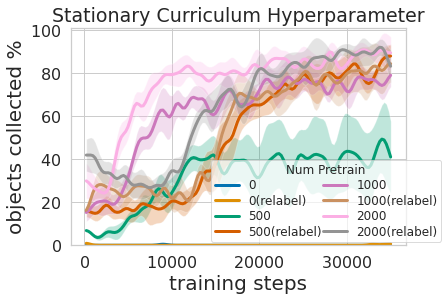
Entrenar esta política multinivel no solo fue más eficiente que aprender ambas habilidades al mismo tiempo, sino que permitió que el controlador de agarre informara la política de navegación. Tener un modelo que estime la incertidumbre en su éxito de agarre (nuestro arriba) se puede usar para mejorar la exploración de navegación saltando áreas sin objetos que se pueden agarrar, en contraste con la bonificación sin incertidumbre que no usa esta información. El modelo también se puede usar para volver a etiquetar los datos durante el entrenamiento, de modo que en el caso desafortunado de que el modelo de agarre no tenga éxito tratando de agarrar un objeto dentro de su alcance, la política de agarre aún puede proporcionar alguna señal al indicar que un objeto estaba allí pero el agarre la política aún no ha aprendido a captarlo. Además, aprender modelos modulares tiene beneficios de ingeniería. La capacitación modular permite reutilizar habilidades que son más fáciles de aprender y puede permitir la construcción de sistemas inteligentes una pieza a la vez. Esto es beneficioso por muchas razones, incluida la evaluación y comprensión de la seguridad.
Lección 2: Los sistemas de aprendizaje superan a los sistemas codificados a mano, con el tiempo
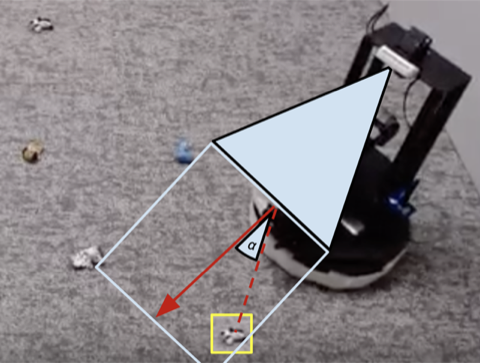
Muchas tareas de robótica que vemos hoy pueden resolverse con diferentes niveles de éxito utilizando controladores diseñados a mano. Para nuestra tarea de limpieza de la habitación, diseñamos un controlador diseñado a mano que localiza objetos mediante el agrupamiento de imágenes y gira hacia el objeto detectado más cercano en cada paso. Este controlador diseñado por expertos funciona muy bien en los calcetines con forma de bola visualmente sobresalientes y toma caminos razonables alrededor de los obstáculos, pero no puede aprender un camino óptimo para recolectar los objetos rápidamente, y tiene problemas con salas visualmente diversas. Como se muestra en el video 3 a continuación, la política del guión se distrae con la alfombra estampada blanca mientras intenta ubicar más objetos blancos para agarrar.



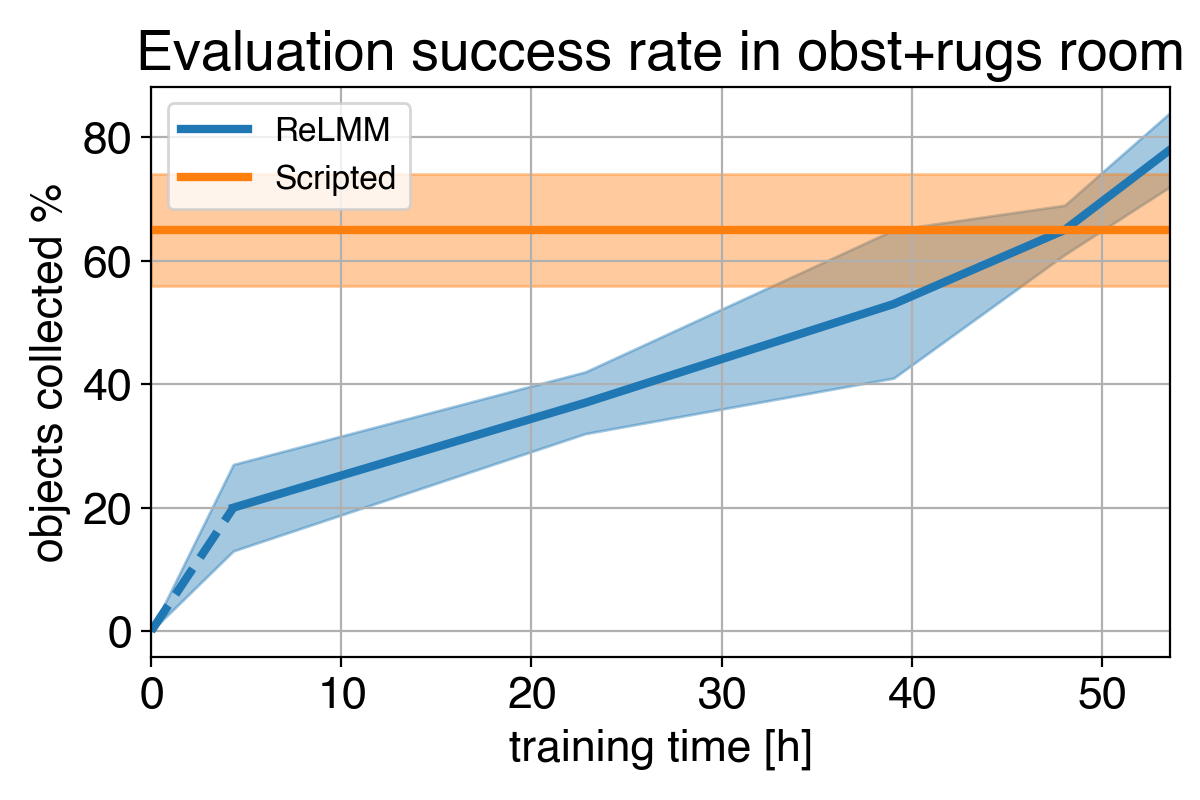
Dado que podemos usar expertos para codificar este controlador diseñado a mano, ¿cuál es el propósito del aprendizaje? Una limitación importante de los controladores hechos a mano es que están ajustados para una tarea en particular, por ejemplo, agarrar objetos blancos. Cuando se introducen diversos objetos, que difieren en color y forma, es posible que la afinación original ya no sea óptima. En lugar de requerir más ingeniería manual, nuestro método basado en el aprendizaje puede adaptarse a diversas tareas mediante la recopilación de su propia experiencia.
Sin embargo, la lección más importante es que incluso si el controlador diseñado a mano es capaz, el agente de aprendizaje eventualmente lo supera con el tiempo suficiente. Este proceso de aprendizaje es en sí mismo autónomo y tiene lugar mientras el robot realiza su trabajo, lo que lo hace comparativamente económico. Esto muestra la capacidad de los agentes de aprendizaje, que también se puede considerar como una forma general de realizar un proceso de «ajuste manual experto» para cualquier tipo de tarea. Los sistemas de aprendizaje tienen la capacidad de crear el algoritmo de control completo para el robot y no se limitan a ajustar algunos parámetros en un script. El paso clave en este trabajo permite que estos sistemas de aprendizaje del mundo real recopilen de forma autónoma los datos necesarios para permitir el éxito de los métodos de aprendizaje.
Leído en: