

¿Por qué términos como inteligencia artificial, aprendizaje automático, aprendizaje profundo… se usan constantemente de manera intercambiable?
En muchas ocasiones se habla del uso de la inteligencia artificial (IA). Apenas hay un producto digital que no afirme apoyarse en la IA. Pero, ¿es eso realmente cierto en todos los casos? ¿Hay IA en todo lo que se denomina IA? Diferencia entre inteligencia artificial – aprendizaje automático – aprendizaje profundo.
¿Qué es realmente la inteligencia artificial?
Según un artículo publicado en The Verge, alrededor de todas las empresas de nueva creación – startup – en Europa son engañosas en ese sentido, y apuestan por decir que trabajan con IA sin utilizar realmente esta tecnología. Por supuesto, la razón también puede ser que muchos no saben exactamente qué es la inteligencia artificial en realidad.
“La inteligencia artificial es la ciencia y la ingeniería que hacen que los ordenadores se comporten de formas que, hasta hace poco, pensábamos que requerían inteligencia humana”.
Andrew Moore, exdecano de la School of Computer Science de la Carnegie Mellon University
Así que se trata de sistemas informáticos que exhiben un comportamiento que anteriormente solo atribuíamos a los humanos. Sin embargo, esta definición sigue siendo muy vaga. De hecho, es difícil definir qué es realmente la inteligencia artificial. Claramente, no son solo esos superpoderes de los guiones de ciencia ficción que, tarde o temprano, tienen la idea de reemplazar a sus creadores humanos con variantes mecánicas mejores.
Definimos inteligencia artificial como una característica de un sistema informático que muestra que el sistema es capaz de generar decisiones con mayor precisión que por pura casualidad utilizando ciertas heurísticas. Por supuesto, esto también incluye algoritmos para la planificación de rutas – como el Algoritmo A* – o un optimizador simple para juegos – como el Algoritmo MiniMax6.
Definimos inteligencia artificial como una característica de un sistema informático. Los primeros ordenadores de ajedrez se desarrollaron hace más de 50 años. En ese momento, una combinación de teoría de juegos y estrategia de juego. Una mezcla que entonces solo se confiaba a los jugadores humanos. Hoy en día, un ordenador de ajedrez probablemente ya no se consideraría una novedad en inteligencia artificial.
La inteligencia artificial con la que nos encontramos constantemente hoy en día está muy dirigida a la comunicación hombre-máquina. Por ejemplo, sistemas de interacción como Siri de Apple, Google Home o Alexa de Amazon, que permiten el control por voz de los procesos digitales. Se puede esperar que, dentro de diez a veinte años, tales dispositivos ya no se consideren inteligentes.
De esta gran área de inteligencia artificial, el segmento de aprendizaje automático ha cobrado cada vez más importancia en los últimos años, y las técnicas utilizadas allí se han beneficiado significativamente de la creciente avalancha de datos.
¿Qué es realmente aprendizaje automático?

Tom M. Mitchell (decano interino de la School of Computer Science de la Carnegie Mellon University, professor y expresidente del Machine Learning Department de la Carnegie Mellon University) formula la pregunta central de cuál es el núcleo de la disciplina de la siguiente manera:
“¿Cómo podemos construir sistemas informáticos que mejoren automáticamente con la experiencia y cuáles son las leyes fundamentales que gobiernan todos los procesos de aprendizaje?”
Entonces, por un lado, se trata de la cuestión de cómo podemos construir un sistema informático que sea capaz de aprender a través de su propia experiencia y, por otro lado, se trata de investigar los impulsores de todos los procesos de aprendizaje.
El aprendizaje automático es una rama separada del campo de la inteligencia artificial. Las técnicas de aprendizaje automático se utilizan para crear sistemas informáticos que pueden reconocer patrones en los datos. Es superficialmente irrelevante qué tipo de datos están involucrados. El objetivo del sistema es extraer patrones que puedan ser utilizados para el proceso de aprendizaje.
Supongamos que proporcionamos un modelo de aprendizaje automático con un conjunto de canciones que hemos disfrutado escuchando en el pasado. El modelo de aprendizaje automático puede, entonces, reconocer patrones en las canciones y compararlas con canciones previamente desconocidas. De esta manera, el modelo puede seleccionar nuevas canciones que probablemente satisfagan mi gusto. Dado que hemos proporcionado los datos de entrada para el modelo con un nombre (“me gusta”), este es un ejemplo de aplicación del área de aprendizaje supervisado. Estos sistemas que generan recomendaciones para el usuario también se denominan sistemas de recomendación.
Aprendizaje supervisado vs. aprendizaje no supervisado
En el caso más simple, si cargamos nuestro modelo de aprendizaje automático con datos de entrada y los etiquetamos, el modelo puede luego asignar entradas similares a estas categorías (o, en otras palabras, clasificarlas). El modelo también analiza las propiedades de los datos de entrada durante la clasificación y compara estas características con los ejemplos de entrenamiento existentes. Con base en este análisis, selecciona la categoría con mayor probabilidad.
Por ejemplo, si nuestro modelo fue entrenado para diagnosticas imágenes de rayos X, luego solo puede procesar imágenes de rayos X de manera significativa.
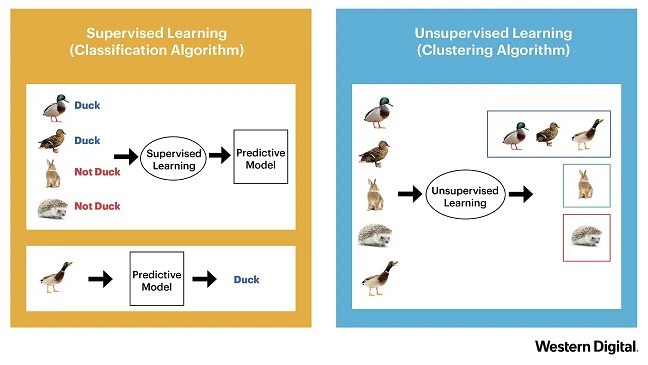
Los modelos de aprendizaje supervisado intentan calcular una función de aproximación que pueda modelar mejor las relaciones entre los datos de entrenamiento y las etiquetas asignadas.
El aprendizaje no supervisado, por otro lado, significa que el modelo forma clústeres e intenta agrupar los datos de entrenamiento. Dependiendo de la tecnología, el desarrollador puede especificar cuántos clústeres de este tipo se deben buscar. Estos modelos no proporcionan una etiqueta, sino que solo agrupan la cantidad de entrada en subconjuntos.
La tercera categoría es el aprendizaje por refuerzo. Refuerzo significa que el sistema recibe retroalimentación de su entorno y planifica sus acciones futuras en función de esta retroalimentación. Después de cada acción, el sistema recibe un estímulo (recompensa) del entorno, que es positivo o negativo con respecto al logro de la meta planificada. Después de eso, el agente de aprendizaje se encuentra en un nuevo estado, y puede extraer la acción más favorable para él de su repertorio.
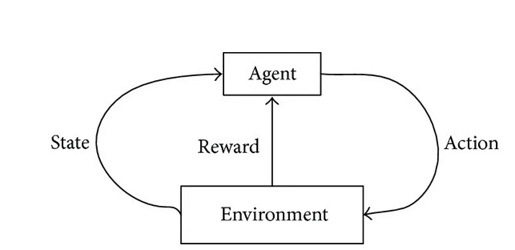
Con el aprendizaje por refuerzo, el proceso de aprendizaje se lleva a cabo de forma continua en el sentido de un bucle de control: esta expansión continua del alcance de la acción puede complementarse idealmente con modelos de aprendizaje supervisado. En particular, los juegos basados en episodios son ideales para una solución que utiliza el aprendizaje por refuerzo. Se remite al lector interesado a la literatura estándar sobre el aprendizaje por refuerzo de Sutton y Barto.
Diferencia entre inteligencia artificial – aprendizaje automático – aprendizaje profundo
¿Por qué términos como inteligencia artificial, aprendizaje automático, aprendizaje profundo… se usan constantemente de manera intercambiable?
El término inteligencia artificial fue acuñado por un grupo de científicos en 1956. Desde entonces, todo el campo de investigación de la inteligencia artificial ha pasado por varios altibajos. Al comienzo de esta era de IA, hubo una fase de exageración. Estimulados por varios programas espaciales y la literatura de ciencia ficción correspondiente, algunos científicos ya creían que estaban muy cerca de una IA similar a la humana. Los fondos de investigación eran fáciles de conseguir.
Sin embargo, esta creencia resultó ser un error y comenzó el invierno de la IA. Un periodo de tiempo en el que los fondos para la investigación y el interés por el foco eran muy escasos.
Más tarde, las empresas utilizaron los diversos términos para destacarse o posicionarse en consecuencia. IBM afirmó que Deep Blue (el ordenador de ajedrez que derrotó por primera vez a Kasparov) no usaba inteligencia artificial, sino que era un superordenador, y Deep Blue claramente usaba técnicas de IA.
Después de eso, aparecieron otros términos como Big Data y Predictive Analytics que también ayudaron al área de Machine Learning a tomar un nuevo impulso. En 2012, las cantidades acumuladas de datos permitieron lograr el éxito utilizando redes neuronales por primera vez.
Desde entonces, la cantidad de datos ha crecido y las redes neuronales se han vuelto cada vez más grandes, lo que acuñó el término aprendizaje profundo. En la era del aprendizaje profundo, el desarrollo de las redes neuronales realmente se aceleró y permitió resolver tareas que antes no eran posibles utilizando sistemas expertos basados en reglas. Ejemplos de esto son el reconocimiento facial, el reconocimiento y el análisis de voz y texto.
Diferencia entre inteligencia artificial – aprendizaje automático – aprendizaje profundo